
Which AI Model Should You Use in 2025? The Smartest Answer Isn’t Just “The Smartest”
- dimosthenis spyridis
- July 24, 2025
- Innovate
- AI Tools, Artificial Intelligence, digital innovation, Innovation Consultancy, TheFutureCats
- 0 Comments
You Don’t Need the “Best” AI Model. You Need the Right One.
Almost every week, a new AI model drops. It promises to be faster, smarter, or cheaper than the last. Right now, Grok 4 is sitting at the top of benchmark leaderboards for intelligence and reasoning.
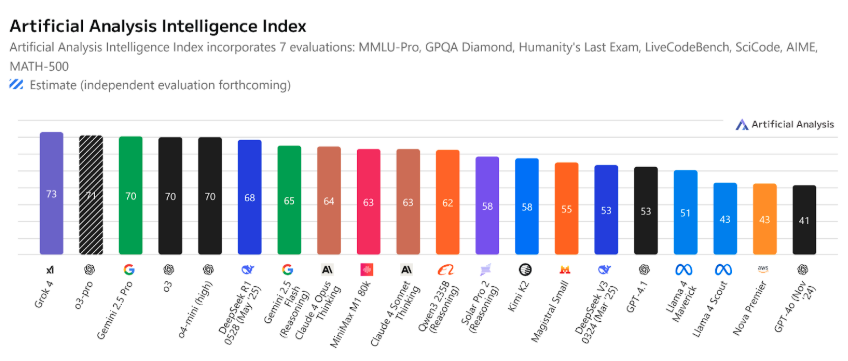
Gemini 2.5 Pro is sweeping text, code, and image tasks with ease. And budget-friendly challengers like DeepSeek R1 are making everyone rethink value per token. Here’s the LM Arena leaderboard:
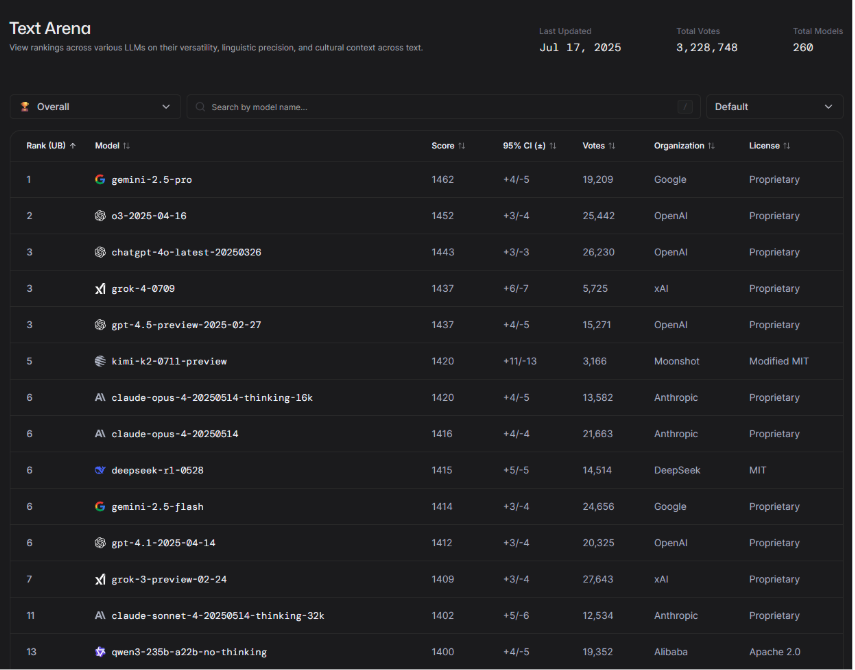
With so many high-performing models on the market, it’s tempting to chase whatever just went viral on LinkedIn or scored highest on Artificial Analysis. But here’s the truth: the model that’s “best” in theory might not be the one that actually works for your team, your timeline, or your tech stack.
This isn’t about picking the top performer. It’s about finding the model that fits your mission.
Benchmarks Are Useful, But They’re Not the Whole Story
Yes, Grok 4 posted the highest intelligence index in recent testing, scoring a 73 and surpassing even OpenAI’s leading models. It also dominated rigorous benchmarks like GPQA Diamond and AIME. Gemini 2.5 Pro, meanwhile, has been lauded for its versatility. It handles text, vision, and coding tasks with consistent performance. DeepSeek R1 comes close in reasoning scores while offering one of the lowest cost-per-token rates available.
These numbers matter. But benchmarks are like lab tests. They don’t always reflect what happens when a model faces real-world context, data noise, or organizational friction.
Think about your last digital tool rollout. What mattered most: raw capability, or whether your team could integrate and adapt quickly? The same applies to AI.
Your Use Case Should Drive Your Model Choice
This is where the conversation often goes off the rails. A common mistake is to default to whatever model gets the highest score, assuming it will work everywhere. But building a generative AI assistant is a different challenge than automating R&D analysis, and those are both different from supporting multilingual civic engagement tools.
Each use case has unique needs. Some require depth of reasoning. Others prioritize speed and responsiveness. Some demand image capabilities. Others rely on massive context windows or explainability.
Let’s say you’re working on internal knowledge synthesis. You might value larger context capacity and fast summarization over subtle logic games. If you’re exploring future policy scenarios, you’ll want a model with strong narrative reasoning and less factual hallucination. And if you’re deploying tools for end users, latency and pricing may become deal-breakers.
So instead of asking which model is “better,” ask what kind of intelligence your work demands. That’s the smarter question.
What’s at Stake: Time, Trust, and Cost
Beyond the technical specs, what’s really at stake here is alignment. Pick the wrong model and you might face a backlog of integration issues, uneven output quality, and rising costs that surprise you at scale.
Trust is another big issue. Some models are extremely capable, but their decisions can feel like black boxes. That makes it hard to explain outcomes to stakeholders. Others are more transparent, offering clearer traces of their reasoning but with trade-offs in nuance or creativity.
And then there’s the cost curve. Grok 4 is powerful, but at six dollars per million tokens, it adds up fast, especially if you’re dealing with large volumes or iterative prototyping. Gemini 2.5 Pro lands in the midrange on pricing and offers a compelling balance of performance and value. DeepSeek R1, on the other hand, gives you roughly 93 percent of Grok’s intelligence for less than a dollar per million tokens. That’s a strategic difference if you’re scaling across multiple teams or use cases.
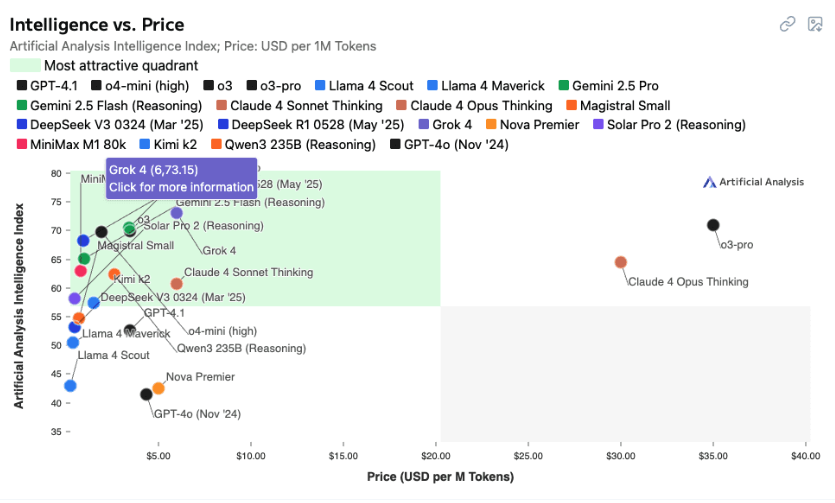
Fit Beats Hype in AI Model Selection
What we’re seeing in 2025 is the end of one-size-fits-all AI. There’s no single model that wins across the board. Instead, different models are showing strengths in specific areas. Some handle images better, others excel at reasoning, while others are best for code or long-form writing. The real question isn’t which one tops the charts, but which one fits your goals, your team, and the way you actually work.
So, the question becomes: How do you find the one that fits?
It starts with translating your vision into technical needs. That might mean prototyping different models against your real data. It could involve assessing the trade-offs between latency and accuracy. Or it might require evaluating a model’s ethical footprint. How it handles bias, where it sources its data, and how easily its outputs can be audited.
This isn’t about being overwhelmed by choice. It’s about being intentional. The model you choose becomes part of your team. It influences not just outputs, but workflows, expectations, and decisions. That’s why model selection isn’t just a technical task. It’s a strategic one.
We Help You Build AI That Works for You
At TheFutureCats, we’ve guided organizations through the process of choosing and integrating AI models that truly serve their needs. Whether you’re building tools for internal transformation, public engagement, or future scenario exploration, the model is never just the tech. It’s the glue between vision and execution.
We don’t just chase benchmarks. We evaluate fit. We look at context. And we help teams make decisions.
So if you’re wondering whether Grok 4, Gemini 2.5 Pro, ChatGPT 4o, or something leaner like DeepSeek R1 is the way to go, start by asking what kind of future you’re trying to build. We’re here to help you build it, one AI model at a time.
Curious which model fits your future?
Let’s find out together. Talk to us.
